コンタクトセンター
コンタクトセンターの後処理における生成AI活用とは?データ品質と生産性の両立

コンタクトセンターの後処理は「データを増やせば現場が疲弊し、減らせば経営に活かせない」というトレードオフを長く抱えてきました。生成AIの登場は、このジレンマを解消する現実的な選択肢になりつつあります。
本記事では、後処理にデータを残しつつオペレーターの負担を抑え、結果として経営改善に直結する応対履歴を作るための具体的な進め方を、現場運営者・SV・管理者の方が明日から検討に着手できる粒度で解説します。生成AI活用の概念論ではなく、現状課題の整理から実装ステップまでを一気通貫で扱います。
コンタクトセンター業務の運営や外注を検討している方が、自社のセンターでどのように生成AIを後処理に組み込むかを判断するための指針として活用いただけると幸いです。
1.本記事の前提:本記事で利用する用語と「後処理」の位置づけ
1-1.本記事で利用する用語の定義
後処理項目:応対履歴に残す情報の入力欄のこと。問い合わせ種別、解決可否、商品名、原因区分、対応内容など、企業によっては数十項目に及ぶこともあります。
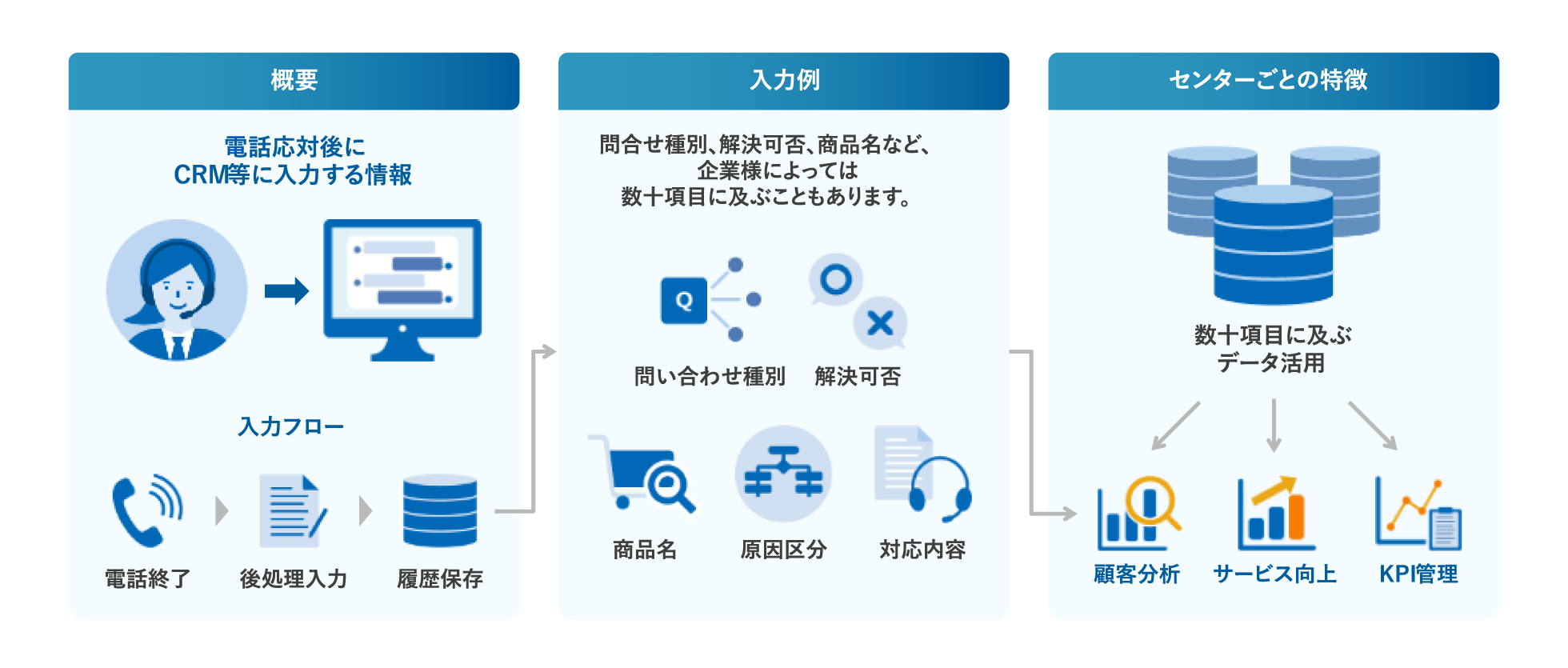
1-2. なぜいま「後処理」が重要なテーマになるのか?
後処理は長らく「コール処理の付随作業」として、生産性指標の足を引っ張る対象と見なされてきました。しかし近年、応対履歴に蓄積されるデータが商品改善・解約防止・FAQ整備・人材育成といった経営課題に直結する一次情報であることが再評価されています。
経営改善という言葉を具体化すると、後処理データの活用先は大きく次の5つに分かれます。
- 商品・サービス改善:苦情や要望の傾向分析から開発・改修要件を抽出する
- 解約防止・LTV向上:解約理由の構造化分析から打ち手を設計する
- オペレーション改善:問い合わせ理由の上位化から自己解決導線を整備し、入電そのものを削減する
- 人材育成・ナレッジ整備:優れた応対パターンや頻出ケースをFAQ・トレーニング素材に反映する
- 問い合わせ数の削減:顧客が自己解決できる環境を構築する
つまり後処理改革は単なる業務効率化ではなく、センターを「コストセンター」から「インサイトセンター」へ転換させるための起点です。生成AIはこの転換を技術的に後押しする存在として位置づけられます。ただし、これらの活用を実現するために応対履歴に記録するデータを増やそうとすると、現場には深刻な課題が発生します。
2. 後処理で記録するデータを増やそうとすると発生する5つの課題
応対履歴データを経営に活かすためには「履歴に残すデータの量と質を高める」必要がありますが、 単純に後処理項目を増やすだけだと、現場には以下に示すような連鎖的な問題が発生します。
2-1. 発生する課題の種類は?
後処理データを増やそうとした際の課題は、観点によって次のように分類できます。
| 観点 | 発生する具体的な事象 |
|---|---|
| 生産性・コスト | ACW(※1)の延伸、CPH(※2)の低下、応答率・放棄呼率の悪化、人件費の増加 |
| 人材・組織 | 業務難易度の上昇、ストレスの増加、離職率の上昇、新人の戦力化期間の長期化 |
| データ品質 | 項目あたりの情報の質の低下、表記揺れの発生、入力漏れ・誤入力の増加 |
| 運用工数 | 履歴品質担保のためのフィードバック工数増、品質チェックの作業量増、教育コストの増加 |
| 顧客体験(CX) | 待ち呼時間の増加、クレームの誘発、顧客満足度やNPS(※3)の低下 |
※1 ACW:顧客との通話が終了した後にオペレーターが行う「平均後処理時間」 ※2 CPH:オペレーター1人が1時間あたりに処理する件数(受電・発信)を指す生産性指標 ※3 NPS:顧客が企業やブランド、サービスに対して持っている「信頼」や「愛着(ロイヤルティ)」を数値化する指標
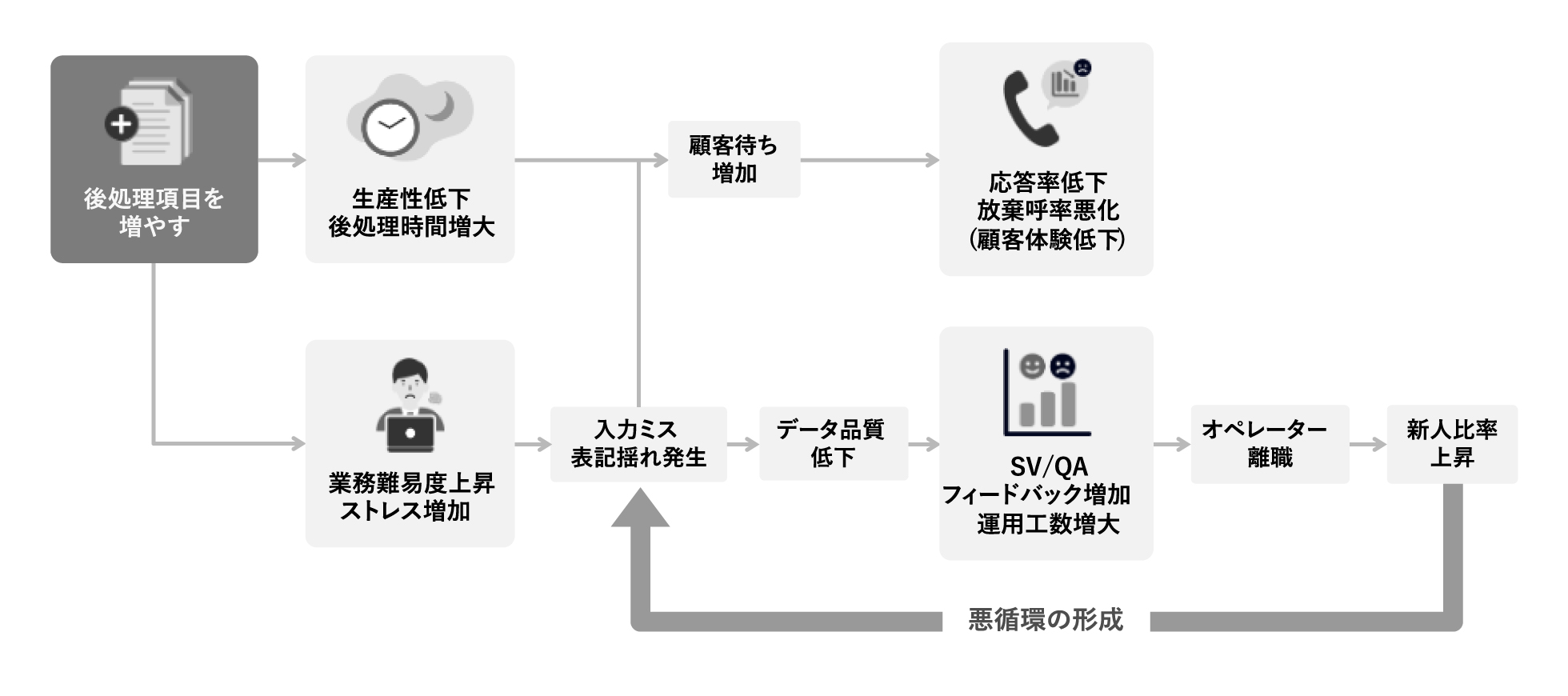
2-2. 各課題の因果関係は?
これら5つの課題は独立しておらず、相互に連動して悪化していく性質を持ちます。 後処理項目を増やすと、まず生産性が下がりACWが長くなります。これに伴って業務難易度が上がり、オペレーターのストレスが増え、入力ミスや表記揺れが発生します。データ品質が下がるため、SVやQA(※4)担当はフィードバックを増やさざるを得ず、運用工数が増大します。同時に、後処理が長引くことで次コール待ちの顧客が増え、応答率の低下や放棄呼率の悪化という形で顧客体験にも跳ね返ります。最終的にオペレーターが離職し、新人の比率が高まることで、また入力品質が下がるという悪循環に陥ります。
※4 QA:オペレーターの応対をモニタリングして、その品質を評価したりフィードバックする担当者
3. 従来の後処理改善アプローチの整理とその限界
後処理データを増やす施策は「後処理項目を追加する」という単純な作業ではなく、前章で示した連鎖を断ち切る仕組みとセットで設計する必要があります。生成AI登場以前は、以下のような手法を組み合わせて対処してきました。ここでは、それぞれの有効性と限界を整理します。
3-1. 主な従来の手法
| 手法 | 概要 | 限界 |
|---|---|---|
| プルダウン化・選択式入力 | 頻出値を事前に列挙してリスト化し、自由記述を減らす | 想定外の値を取りこぼし、「その他」にデータが集まる。粒度が粗くなり示唆出しに限界 |
| 後処理項目数の妥協 | 現場負荷を優先して項目数を絞り、不足分を後付けで集計 | 工数が部署横断的に発生。リアルタイム性に欠ける |
| 顧客による情報入力補助 | Web画面やSMSで顧客自身に情報入力してもらう | 入力ステップを増やすこと自体が顧客負担の増大につながり、CXや回答完遂率の低下。母集団の偏りを招き、データ分析の信頼性が低下する。 |
| 人材を絞った施策実行 | 特定の担当者に施策を限定して実施し、その結果をサンプリング調査として全体傾向を推定する | 限られた人数による検証のため、十分なサンプル数が確保できず統計的な信頼性に限界がある |
| RPAによる入力自動化 | 他システム参照・転記を自動化 | 判断を伴う入力は自動化困難 |
| 統計・自然言語処理による分析 | 蓄積データから分析モデルを構築 | データサイエンスの知見と学習データ整備が必要。導入・運用コストが高い |
3-2. 従来手法に共通する構造的限界
個々の手法には一定の効果がありましたが、いずれも次のような構造的限界を抱えていました。
- 担い手の制約:自由記述から構造化データを生成する作業を、人手か高度なエンジニアリングのいずれかでまかなう必要があった
- トレードオフの壁:「現場負担を増やさず」「データ品質を担保し」「分析しやすい形に整える」の三つを同時に満たすことが難しかった
これらの構造的限界に対し、生成AIは決定的な変化をもたらしました。従来は「人手」か「高度なエンジニアリング」でしか実現できなかった自由記述の構造化が、生成AIの登場により簡単に実行できるようになったのです。
4. 【基本】 生成AIを活用した後処理を実施するためのステップ
本章では、生成AIを後処理業務に組み込む際に押さえるべき手順を、現状把握から全体展開まで9つのステップに分けて解説します。
ステップ1:現状の後処理項目とトークスクリプトを棚卸しする
本格的な設計に入る前に、現在運用されている後処理項目・トークスクリプトを一覧化し、各項目の入力率、データ分析における課題を可視化します。
ステップ2:応対履歴の作成目的を言語化し、優先順位を付ける
商品・サービス改善/再入電時の対応/オペレーター教育/ナレッジ作成などに関する内容を具体的に明文化します。優先順位の判断は、経営課題への寄与度と、データ取得の難易度の両面から行います。
ステップ3:目的から逆算して後処理項目を設計する
分析シナリオから必要な後処理項目について階層構造を設計します。既存項目との差分を明示的に管理し、CRMやCTI側のシステム改修が必要な場合はIT部門への依頼内容と所要期間を確認してください。
ステップ4:データ収集のためのトークスクリプトを設計・再構築する
後処理項目を精緻に設計しても、トークスクリプトの品質が悪ければ目的のデータは集まりません。スクリプト設計の品質は「ヒアリング項目の網羅性」「顧客が違和感を持たない自然な流れ」「オペレーター間でばらつかない具体性」の3点で評価します。
ステップ5:生成AIのプロンプトと運用フローを設計する
要約・分類・タグ付けのテンプレートを作成し、出力形式を固定します。あわせて、ハルシネーション対策(参照根拠の明示、確信度の出力、判断不能時の「不明」出力ルールなど)と、AIが正しく出力できなかった場合のオペレーター側のリカバリ手順も併せて設計します。プロンプトは継続改善されるためバージョン管理の仕組みも合わせて整えてください。
ステップ6:実物または疑似対話ログで生成AIの品質と分析可能性を机上検証する
パイロットに進む前に、机上で生成AIの出力品質と、得られたデータでの分析可能性を確認します。検証では2つの軸に分けて評価することが重要です。第一に「AI出力そのものの精度」(要約の正確性、分類の妥当性、タグ付けの一貫性など)、第二に「現状の後処理項目で目的を満たす分析が可能か」という上位の問いです。前者が合格でも後者で項目不足が見つかれば、ステップ2まで戻って再設計が必要になります。
ステップ7:少数人数でパイロットテストを実施する
参加者の選定では、熟練者と中堅・新人をバランスよく含めることで、スキルレベルによる影響を切り分けられます。パイロット参加者には「失敗を報告することがミッション」というメッセージを明示し、心理的安全性を確保してください。あわせて、開始前にパイロットの成功・失敗判断基準(どのKPIがどの水準なら次に進むか)を必ず文書化しておきます。
ステップ8:課題を抽出し、再設計を繰り返す
後処理項目・トークスクリプト・プロンプトの3つを並行で改善します。改善ループは無限に続けられるため、「修正コストに対して期待される改善幅」が一定水準を下回ったら次のステップに進む、というように打ち切り基準を事前に決めておくことを推奨します。
ステップ9:全体展開する
段階的な展開計画を組み、レポーティングラインを定義します。展開の単位は、拠点別/窓口別/オペレーター層別のいずれかから、自社の組織構造に合わせて選択してください。あわせて、展開後に重大な問題が発生した場合の切り戻し計画(旧運用への戻し方、戻すまでの判断時間)と、展開期間中の現場サポート体制(ヘルプデスク窓口、SVへのエスカレーションパス、想定FAQの整備)を必ず用意してください。
5. 【応用】 ダッシュボードで絞り、生成AIで深める — AI協働型ドリルダウン分析
前章では、生成AIを後処理に組み込むための基本ステップを解説しました。本章ではその応用編として、構築した後処理基盤を経営判断に直結させるための分析手法「AI協働型ドリルダウン分析」を紹介します。
5-1. 協働型ドリルダウン分析の全体像
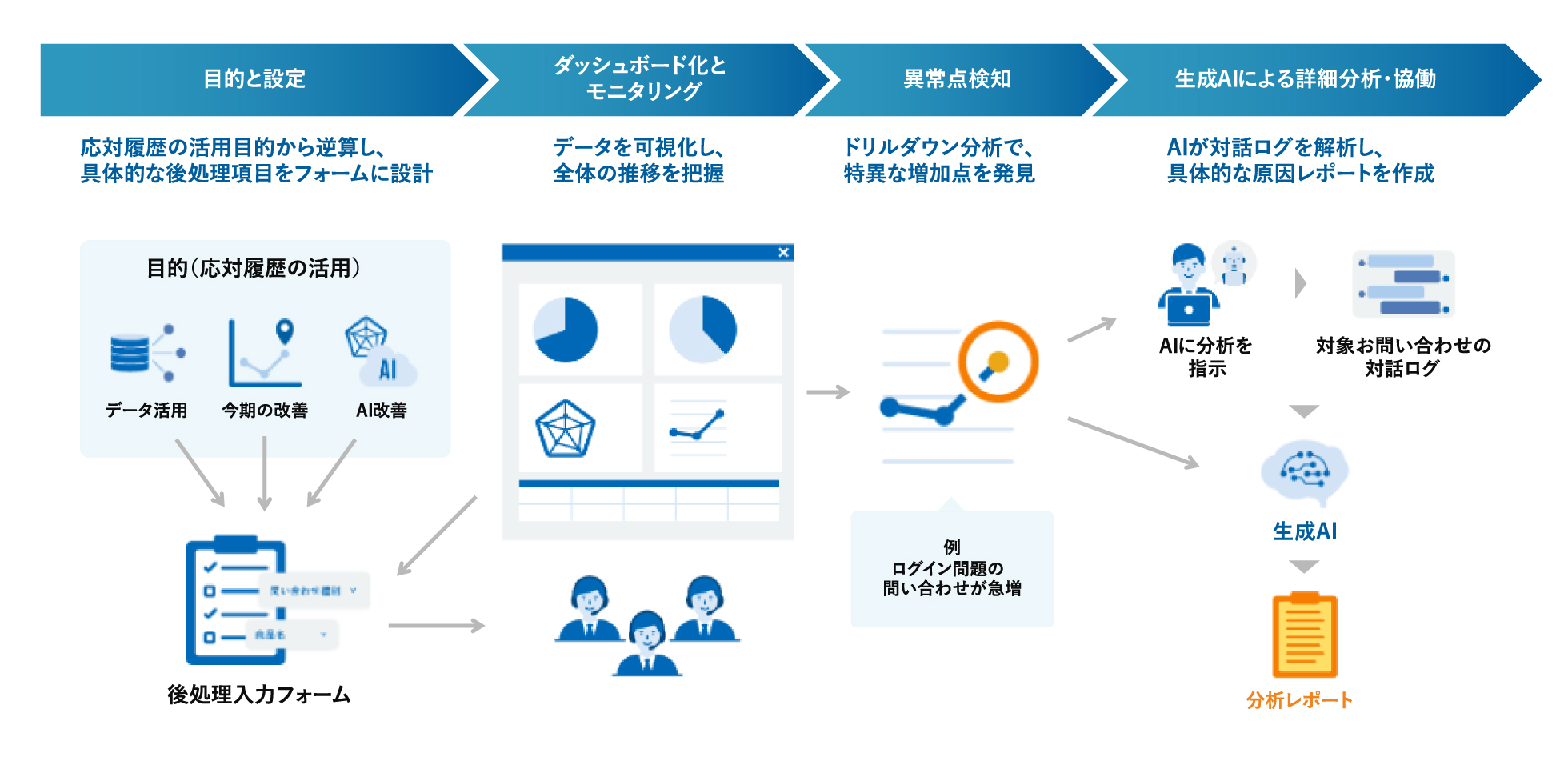
5-2. 協働型ドリルダウン分析の概要
1. 目的の定義と出力項目への逆算
詳細は「4.基本】生成AIを活用した後処理を実施するためのステップ」をご参照ください。
2. データ蓄積とダッシュボードによる可視化
構築した仕組みから蓄積されるデータを、リアルタイムでダッシュボードへ可視化します。 全体像の把握だけでなく、課題の所在を瞬時に特定できるよう、ドリルダウンが可能な設計にすることが、精度の高い分析への鍵となります。
3. 異常点の検知と「ヒト」による仮説構築
数値の急増や変化などの「異常点」を検知した際、まずは初期仮説を構築します。 現場の感覚や背景知識を活かし、「なぜこの問い合わせが増えているのか?」という要因の仮説を組み立てることが、次ステップで生成AIとより良い協働を行うための秘訣です。
4. 生成AIによる詳細分析と知見の深化
検知された異常点に関連する膨大な対話ログを、生成AIに読み込ませます。プロンプトに基づき、構造化された分析レポートを即座に生成。「ヒトが立てた仮説」と「AIが導き出した分析結果」を突き合わせることで、単なるデータ集計を超えた、次のアクションに直結する深い洞察を得ることができます。
5-3. 生成AIに渡すデータを、なぜ人間が事前に選別すべきなのか?
生成AIに分析を任せる際、「とにかく全データを投げれば良い回答が返ってくる」 という発想は誤りです。実際には、人間が分析目的に沿ってデータを事前に絞り込むほど、 回答の精度は上がり、コストは下がります。 前章で解説したドリダウン型ダッシュボードによる「データの事前絞り込み」が「ヒトとAIの協働」の出発点になる理由は、 以下の2点に集約されます。
理由1:必要な情報だけを生成AIに渡すことができる(ノイズを減らす)
山盛りの資料を全て渡すのではなく、本当に必要なページだけを渡すイメージです。 不要な情報が混ざらないため、AIが的外れな回答をするのを防げます。
理由2:生成AIのパンクを防ぎ、生成AI利用コストも下げる(データ量の最適化)
生成AIに目的と関係のない情報を詰め込みすぎると、肝心な内容が埋もれてしまいます。必要なデータだけに絞れば、AIが本質に集中できるため見落としが減り、あわせてトークン料金の節約にもつながります。
6. まとめ|後処理改革は「目的から逆算した項目設計」と「ヒトとAIの役割分担」から
コンタクトセンターの後処理は、長らく「現場負担を増やせばデータ品質が下がり、減らせば経営に活かせない」というジレンマを抱えてきました。本記事で示したとおり、生成AIはこのジレンマを解く鍵になります。ただし、ツールを導入するだけでは効果は出ません。重要なのは、次の2点を自社の業務プロセスに落とし込むことです。
1.目的から逆算した後処理項目の設計
応対履歴を何に活かすのかを定義し、必要な粒度の項目とトークスクリプトを設計してはじめて、生成AIは意味のあるアウトプットを返します。項目設計を曖昧にしたまま生成AIを導入しても、得られるのは「もっともらしいが活用しにくいデータ」に留まります。
2. 「人とAIの役割分担」の明確化
本記事で提唱したAI協働型ドリルダウン分析では、人間がダッシュボードで対象を絞り仮説と問いを立て、生成AIが膨大なログから構造化された洞察を引き出す——という二段構えで価値を生みます。AIに丸投げするのではなく、ヒトの判断を起点にAIを使うことで、分析精度・コスト・スピードのいずれも最適化できます。
後処理改革の出発点は、大規模な投資でも高度なエンジニアリングでもありません。現状の後処理項目とトークスクリプトを棚卸しし、「何のためにこのデータを取るのか」を言語化することから始まります。本記事のステップ0〜8を踏まえ、自社のセンターを「コストセンター」から「インサイトセンター」へ転換させる第一歩を、ぜひ今日から検討してみてください。

執筆者 | 鵜森 洋旭
NTTマーケティングアクトProCX
スーパーバイザー









